R軟件stm包實(shí)操 比LDA更強(qiáng)大的文本處理程序包詳解,助力網(wǎng)絡(luò)與信息安全軟件開發(fā)
隨著大數(shù)據(jù)時(shí)代的深入發(fā)展,文本數(shù)據(jù)已成為網(wǎng)絡(luò)與信息安全領(lǐng)域不可或缺的情報(bào)來(lái)源。從海量的網(wǎng)絡(luò)日志、社交媒體言論到安全報(bào)告,有效挖掘文本中的主題與模式對(duì)于威脅檢測(cè)、輿情監(jiān)控和態(tài)勢(shì)感知至關(guān)重要。在文本主題建模領(lǐng)域,潛在狄利克雷分配(LDA)模型曾長(zhǎng)期占據(jù)主導(dǎo)地位。如今有一個(gè)更強(qiáng)大的工具已經(jīng)上線——R語(yǔ)言中的結(jié)構(gòu)化主題模型(Structural Topic Model, STM)程序包。它不僅在建模能力上超越了傳統(tǒng)LDA,更因其靈活性和對(duì)元數(shù)據(jù)的整合能力,為網(wǎng)絡(luò)與信息安全軟件開發(fā)注入了新的活力。本文將深入解說STM包的核心優(yōu)勢(shì),并提供基礎(chǔ)實(shí)操指南。
一、為什么STM比LDA更強(qiáng)大?
傳統(tǒng)LDA模型將文檔視為詞的集合,并假設(shè)文檔主題分布的先驗(yàn)是固定的(對(duì)稱狄利克雷分布)。雖然經(jīng)典,但其局限性也顯而易見:
- 無(wú)法融入文檔級(jí)元數(shù)據(jù):LDA無(wú)法直接利用與文檔相關(guān)的額外信息,如文檔的作者、發(fā)布時(shí)間、來(lái)源網(wǎng)站類型(在安全領(lǐng)域,可能是攻擊類型、威脅等級(jí)、IP歸屬地等)。這些元數(shù)據(jù)往往包含關(guān)鍵的結(jié)構(gòu)性信息。
- 主題內(nèi)容固定不變:LDA假設(shè)詞匯在主題中的分布不隨文檔特征變化。而在現(xiàn)實(shí)中,同一個(gè)主題(如“網(wǎng)絡(luò)釣魚”)在不同來(lái)源(如社交媒體與暗網(wǎng)論壇)或不同時(shí)期,其表達(dá)用詞可能顯著不同。
STM模型正是為解決這些問題而生。其核心強(qiáng)大之處在于:
- 結(jié)構(gòu)化先驗(yàn):STM允許文檔的主題比例(主題流行度)和主題本身的內(nèi)容(詞分布)都受到文檔元數(shù)據(jù)的直接影響。這意味著我們可以建模“某個(gè)特定來(lái)源的文檔更傾向于討論某個(gè)主題”,或者“在某個(gè)時(shí)間段,某個(gè)主題的表述方式發(fā)生了演變”。
- 豐富的協(xié)變量:可以同時(shí)引入影響主題流行度(
prevalence)和主題內(nèi)容(content)的協(xié)變量(即元數(shù)據(jù)),使得模型更貼近真實(shí)數(shù)據(jù)生成過程。
對(duì)于網(wǎng)絡(luò)與信息安全應(yīng)用,這意味著我們可以構(gòu)建更精細(xì)的模型。例如,分析黑客論壇數(shù)據(jù)時(shí),可以建模“攻擊技術(shù)”這一主題的討論熱度如何隨論壇板塊(元數(shù)據(jù))變化,以及“勒索軟件”主題的用詞在攻擊事件爆發(fā)前后(時(shí)間元數(shù)據(jù))有何不同。這為追溯威脅源頭、刻畫攻擊者畫像提供了更強(qiáng)大的分析工具。
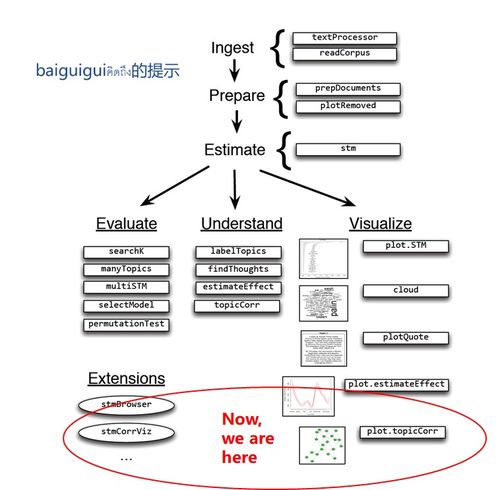
二、STM包基礎(chǔ)實(shí)操步驟
以下是在R環(huán)境中使用stm包進(jìn)行文本主題建模的一個(gè)簡(jiǎn)明流程。假設(shè)我們已有一個(gè)來(lái)自安全告警日志的文本數(shù)據(jù)集 security_data,包含文本字段 text 和元數(shù)據(jù)字段 source(來(lái)源)、date(日期)。
步驟1:環(huán)境準(zhǔn)備與數(shù)據(jù)預(yù)處理
`r
# 安裝并加載必要的包
install.packages("stm")
install.packages("quanteda") # 用于文本處理
library(stm)
library(quanteda)
1. 文本預(yù)處理:創(chuàng)建文檔-詞矩陣(DFM)
假設(shè) df 是數(shù)據(jù)框,包含‘text’和元數(shù)據(jù)列
processed <- textProcessor(df$text,
metadata = df,
lowercase = TRUE,
removestopwords = TRUE,
removenumbers = TRUE,
removepunctuation = TRUE,
stem = TRUE) # 詞干化
2. 準(zhǔn)備STM分析所需的數(shù)據(jù)結(jié)構(gòu)
out <- prepDocuments(processed$documents,
processed$vocab,
processed$meta,
lower.thresh = 5) # 剔除出現(xiàn)少于5次的詞
out對(duì)象包含了STM所需的文檔、詞匯表和元數(shù)據(jù)
`
步驟2:運(yùn)行STM模型
這是最核心的一步,我們可以指定元數(shù)據(jù)如何影響模型。
`r
# 簡(jiǎn)單模型:僅指定主題數(shù)K,無(wú)元數(shù)據(jù)(此時(shí)類似于LDA)
model_lda <- stm(documents = out$documents,
vocab = out$vocab,
K = 10, # 假設(shè)我們尋找10個(gè)主題
data = out$meta,
max.em.its = 75, # 最大迭代次數(shù)
init.type = "Spectral") # 推薦初始化方法
結(jié)構(gòu)化模型:讓“來(lái)源(source)”影響主題流行度
model_stm <- stm(documents = out$documents,
vocab = out$vocab,
K = 10,
prevalence = ~ source, # 關(guān)鍵!主題比例受source影響
data = out$meta,
max.em.its = 75)
更復(fù)雜的模型:同時(shí)讓來(lái)源影響主題流行度,并讓日期影響主題內(nèi)容
modelstmadv <- stm(documents = out$documents,
vocab = out$vocab,
K = 10,
prevalence = ~ source,
content = ~ date, # 關(guān)鍵!主題內(nèi)容隨時(shí)間變化
data = out$meta,
max.em.its = 75)`
步驟3:模型結(jié)果解讀與可視化
stm包提供了豐富的函數(shù)來(lái)理解和展示結(jié)果。
`r
# 1. 查看高頻詞和主題標(biāo)簽
labelTopics(model_stm, topics = 1:10)
# 它會(huì)顯示每個(gè)主題下概率最高、FREX值最高(獨(dú)特且頻繁)的詞,幫助理解主題含義。
2. 可視化主題間關(guān)系(基于語(yǔ)義相似度)
library(ggplot2)
mod.out.corr <- topicCorr(model_stm) # 計(jì)算主題相關(guān)性
plot(mod.out.corr) # 繪制主題網(wǎng)絡(luò)圖,關(guān)聯(lián)緊密的主題會(huì)聚集在一起。
3. 評(píng)估元數(shù)據(jù)效應(yīng)(例如,不同來(lái)源對(duì)主題1流行度的影響)
prep <- estimateEffect(1:10 ~ source, modelstm, meta = out$meta)
summary(prep) # 查看統(tǒng)計(jì)顯著性
plot(prep, covariate = "source", model = modelstm, method = "difference",
topics = 1, # 繪制主題1
xlab = "來(lái)源A相比來(lái)源B在主題1上的流行度差異") # 可視化效應(yīng)
4. 可視化主題內(nèi)容隨元數(shù)據(jù)的變化(如果指定了content協(xié)變量)
plot(modelstmadv, type = "perspectives", topics = c(1, 2))
# 這可以展示同一個(gè)主題下,不同日期(或其它c(diǎn)ontent協(xié)變量)的用詞差異。
`
三、在網(wǎng)絡(luò)與信息安全軟件開發(fā)中的應(yīng)用啟示
將STM整合進(jìn)安全軟件開發(fā),可以極大地提升系統(tǒng)的智能分析能力:
- 動(dòng)態(tài)威脅情報(bào)挖掘:自動(dòng)化處理來(lái)自開源情報(bào)(OSINT)、暗網(wǎng)論壇、漏洞數(shù)據(jù)庫(kù)的文本,利用時(shí)間、來(lái)源等元數(shù)據(jù)建模,實(shí)時(shí)發(fā)現(xiàn)新興攻擊話題、技術(shù)演進(jìn)趨勢(shì)和活躍威脅組織。
- 智能化日志分析:安全運(yùn)營(yíng)中心(SOC)每日處理海量告警日志。STM可以對(duì)這些日志的文本描述進(jìn)行主題建模,并結(jié)合告警等級(jí)、資產(chǎn)類型、地理位置等元數(shù)據(jù),自動(dòng)聚類出高優(yōu)先級(jí)的攻擊模式(如“針對(duì)金融部門的針對(duì)性釣魚”主題),輔助分析師快速聚焦。
- 輿情與內(nèi)部風(fēng)險(xiǎn)監(jiān)控:在內(nèi)部通訊或公開社交媒體數(shù)據(jù)中,通過建模主題流行度與部門、時(shí)間段的關(guān)系,及時(shí)發(fā)現(xiàn)異常討論熱點(diǎn)(如可能的數(shù)據(jù)泄露討論、不滿情緒聚集),實(shí)現(xiàn) proactive 的風(fēng)險(xiǎn)防范。
- 生成式安全報(bào)告輔助:利用STM模型識(shí)別出的核心主題及其代表性文檔,可以自動(dòng)生成安全周報(bào)/月報(bào)的初稿,概括本期主要安全事件類型、影響范圍和演變情況。
###
R語(yǔ)言的stm包通過引入結(jié)構(gòu)化先驗(yàn),成功突破了傳統(tǒng)LDA模型的局限,為處理復(fù)雜的、帶有豐富元數(shù)據(jù)的文本數(shù)據(jù)提供了強(qiáng)大武器。對(duì)于網(wǎng)絡(luò)與信息安全這一高度依賴上下文和關(guān)聯(lián)信息的領(lǐng)域而言,STM不僅僅是一個(gè)“更強(qiáng)大的主題模型”,更是一個(gè)能夠?qū)⒎墙Y(jié)構(gòu)化文本與結(jié)構(gòu)化元數(shù)據(jù)深度融合的分析框架。從研究到開發(fā),掌握STM的實(shí)操,意味著能夠?yàn)橄乱淮悄馨踩治鲕浖蛟旄翡J的“文本感知”能力。趕緊上手嘗試,讓您的安全數(shù)據(jù)“開口說話”吧!
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.sunzhiqiang.com.cn/product/48.html
更新時(shí)間:2026-06-08 21:55:05